
Discussion

Farhad Rahimi
Researcher
What is natural language processing?
Natural Language Processing (NLP) is a branch of AI that enables computers to understand and interpret text and spoken words, similar to how humans do. In today’s digital landscape, organizations accumulate vast amounts of data from different sources, such as emails, text messages, social media posts, videos, and audio recordings. NLP allows organizations to process and make sense of this data automatically. With NLP, computers can analyze the intent and sentiment behind human communication. From customer service chatbots in retailing to interpreting and summarizing electronic health records in medicine, NLP plays an important role in enhancing user experiences and interactions across industries.
Farhad Rahimi
Researcher
Text Preprocessing in NLP
Natural Language Processing (NLP) has seen tremendous growth and development, becoming an integral part of various applications, from chatbots to sentiment analysis. One of the foundational steps in NLP is text preprocessing, which involves cleaning and preparing raw text data for further analysis or model training. Proper text preprocessing can significantly impact the performance and accuracy of NLP models.
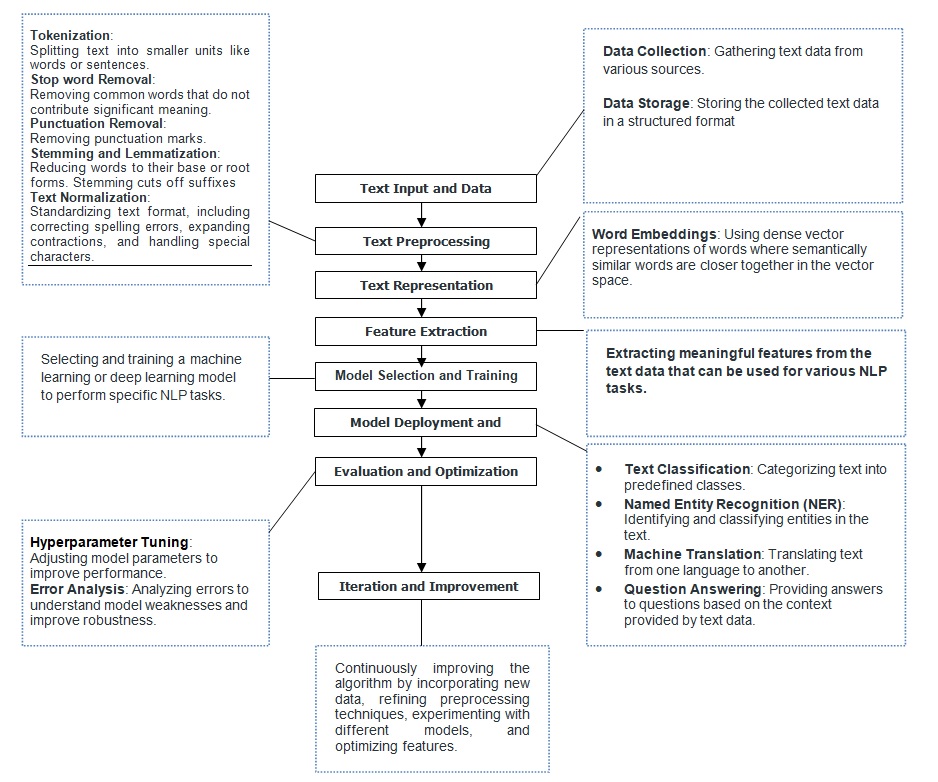
Working in natural language processing (NLP) typically involves using computational techniques to analyze and understand human language. This can include tasks such as language understanding, language generation, and language interaction. It includes steps such as Text Input and Data Collection, Text Preprocessing, Text Representation, Feature Extraction, Model Selection and Training, Model Deployment and Inference, Evaluation and Optimization, Iteration and Improvement .
Farhad Rahimi
Researcher
Why Text Preprocessing is Important?
Raw text data is often noisy and unstructured, containing various inconsistencies such as typos, slang, abbreviations, and irrelevant information. Preprocessing helps in:
Improving Data Quality: Removing noise and irrelevant information ensures that the data fed into the model is clean and consistent.
Enhancing Model Performance: Well-preprocessed text can lead to better feature extraction, improving the performance of NLP models.
Reducing Complexity: Simplifying the text data can reduce the computational complexity and make the models more efficient.
Data is the new currency with which companies can optimize their business processes and address customers in a more targeted manner. This is why analyzing text data, for example, has a central role to play in decision-making.
NLTK (Natural Language Toolkit):
NLTK is a comprehensive library for natural language processing. It offers a variety of tools for Tokenizationstemming, lemmatization, POS tagging and more. Extensive resources such as dictionaries and corpora are also available.
spaCy:
As a modern and efficient library for natural language processing, spaCy provides pre-trained models for tasks such as tokenization, POS tagging and Named Entity Recognition (NER) ready. It is known for its speed and user-friendliness.
TextBlob:
TextBlob is based on NLTK and simplifies many of the text analysis tasks. This library is particularly user-friendly and is ideal for beginners. TextBlob offers functions such as sentiment analysis, extraction of noun phrases and more.
Farhad Rahimi
Researcher
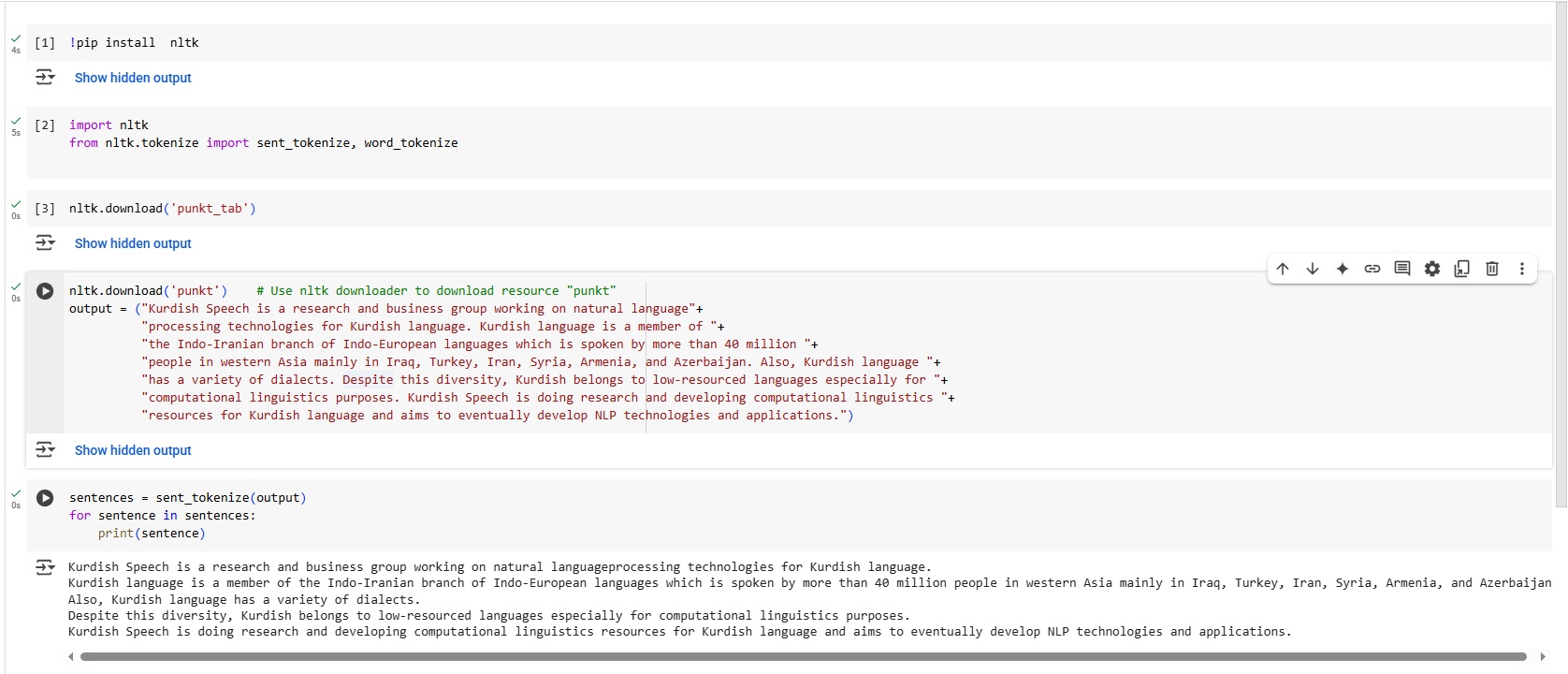
Tokenization
Tokenization refers to a process of segmenting input text into words, punctuation, etc. It allows you to identify the basic units in your text that are called tokens.
By tokenizing, you can conveniently split up text by word or by sentence. This will allow you to work with smaller pieces of text that are still relatively coherent and meaningful even outside of the context of the rest of the text. It’s your first step in turning unstructured data into structured data, which is easier to analyze.
When you’re analyzing text, you’ll be tokenizing by word and tokenizing by sentence. Here’s what both types of tokenization bring to the table:
Tokenizing by word: Words are like the atoms of natural language. They’re the smallest unit of meaning that still makes sense on its own. Tokenizing your text by word allows you to identify words that come up particularly often.
Tokenizing by sentence: When you tokenize by sentence, you can analyze how those words relate to one another and see more context.
Sentence Detection (Sentence Boundary Detection)
Sentence Boundary Detection locates the start and end of sentences in a given text. You can divide a text into linguistically meaningful units to perform tasks such as part of speech tagging and entity extraction.
Farhad Rahimi
Researcher
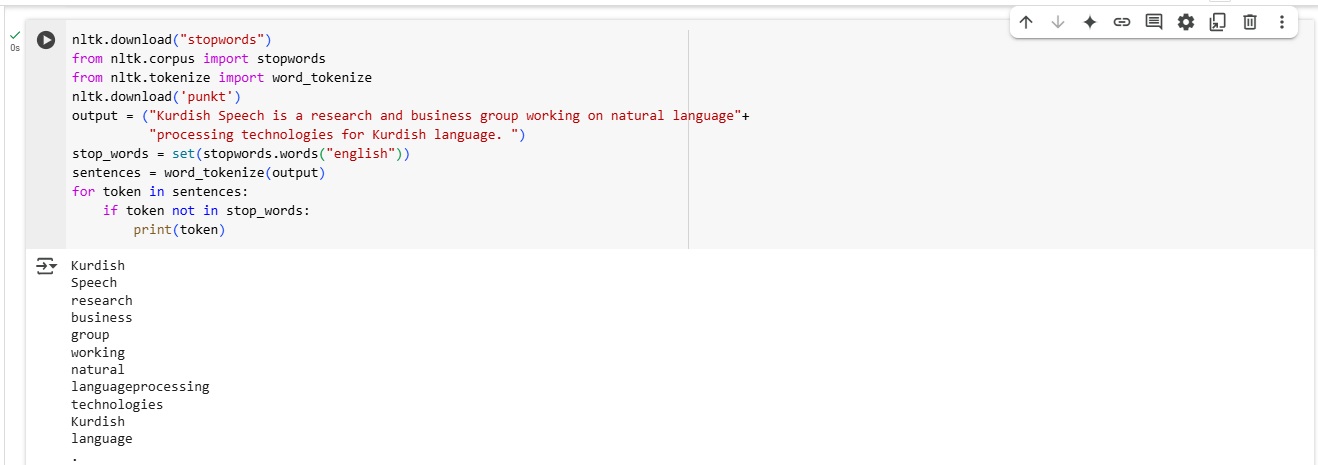
Stop Words Removal
Stop words are the most common words in a language. Examples of stop words are the, who, too, and is. We usually remove the stop words because they are not significant in many text mining tasks such as word frequency analysis. You can identify and remove stop words by using NLTK's list of stop words after tokenizing the text.
Farhad Rahimi
Researcher
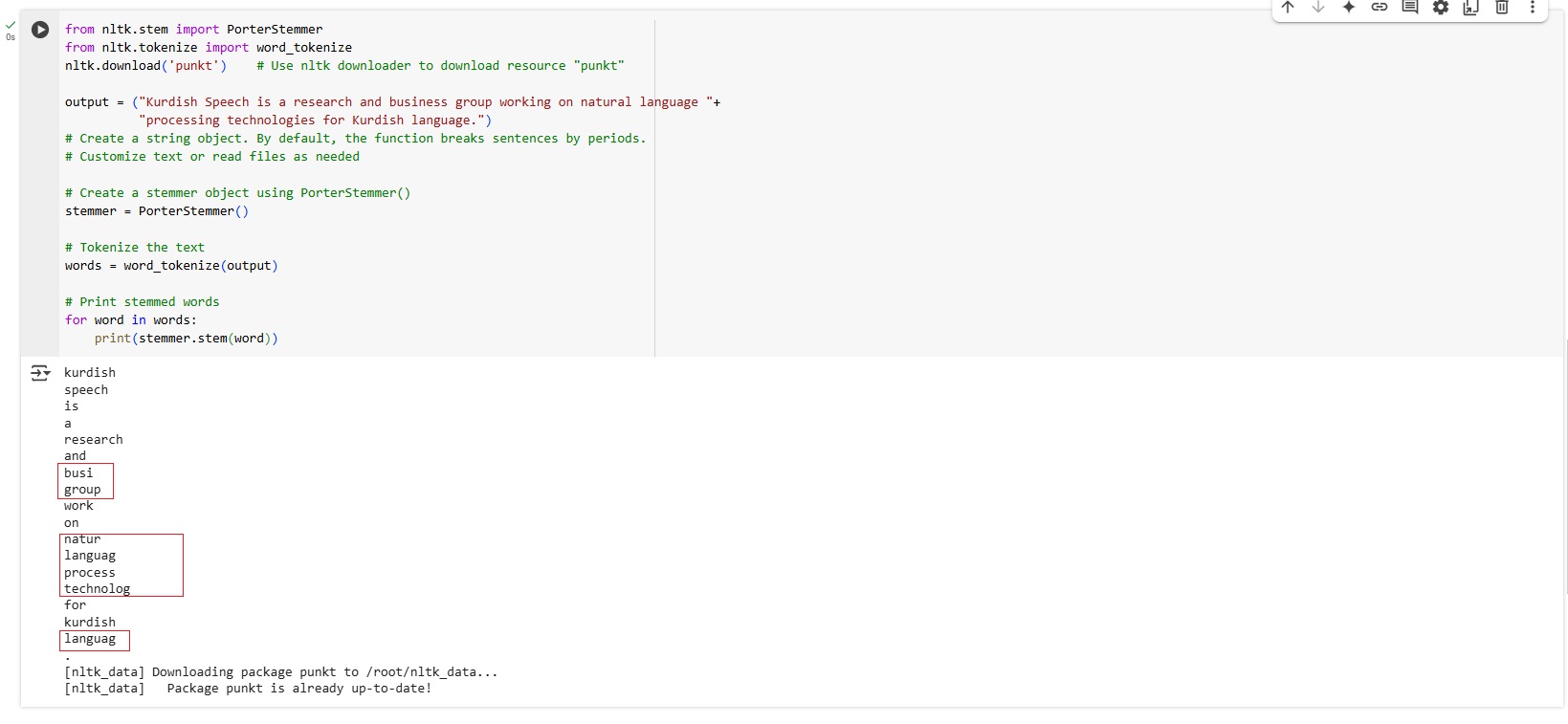
Stemming
Stemming refers to a text processing task that reduces words to their root. For example, the words "adventure", "adventurer", and "adventurous" share the root adventur.” Stemming allows us to reduce the complexity of the textual data so that we do not have to worry about the details of how each word was used.
Farhad Rahimi
Researcher
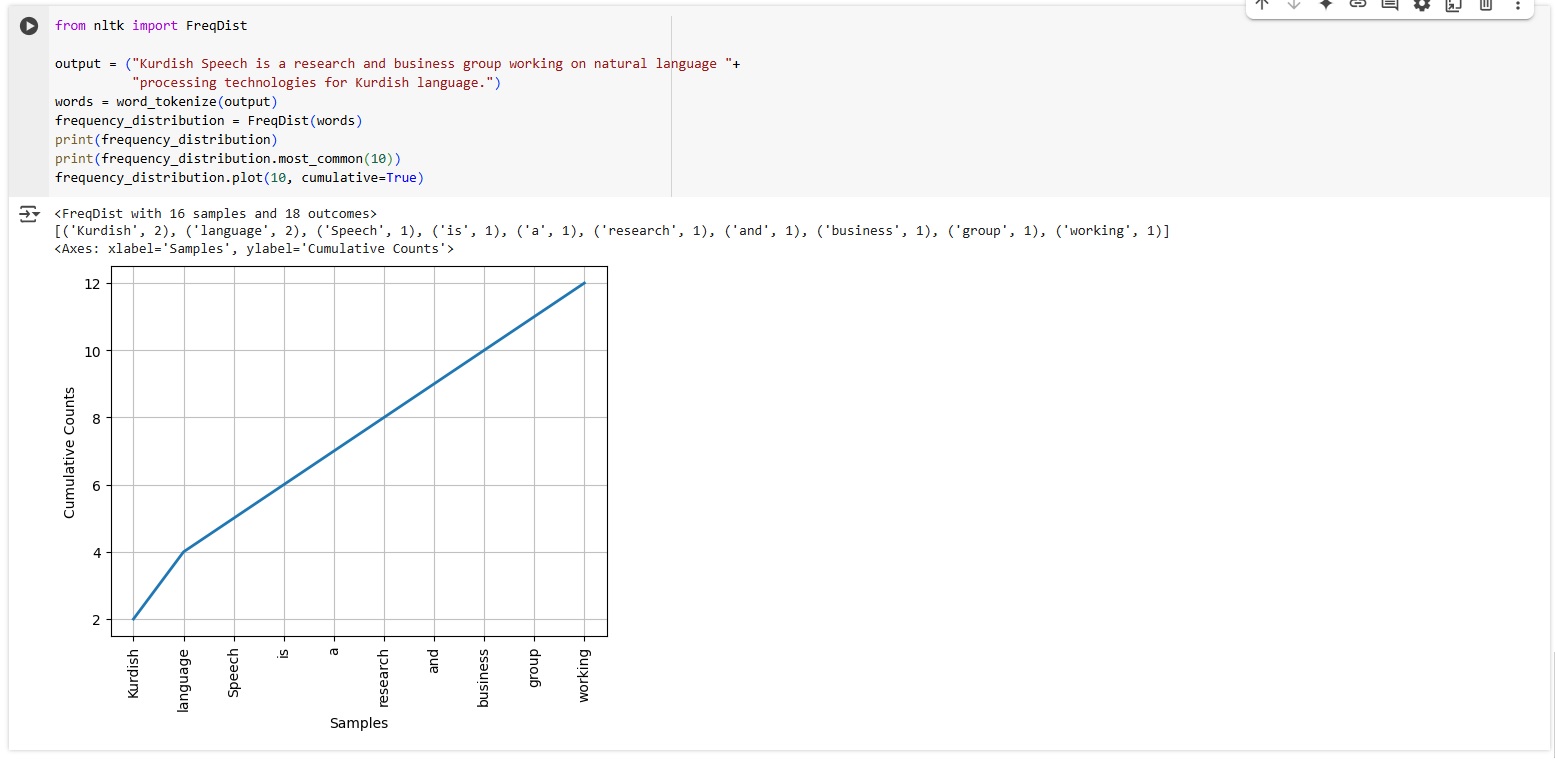
Word Frequency
Word frequency is an analysis that gives you insights into word patterns, such as common words or unique words in the text.
Farhad Rahimi
Researcher
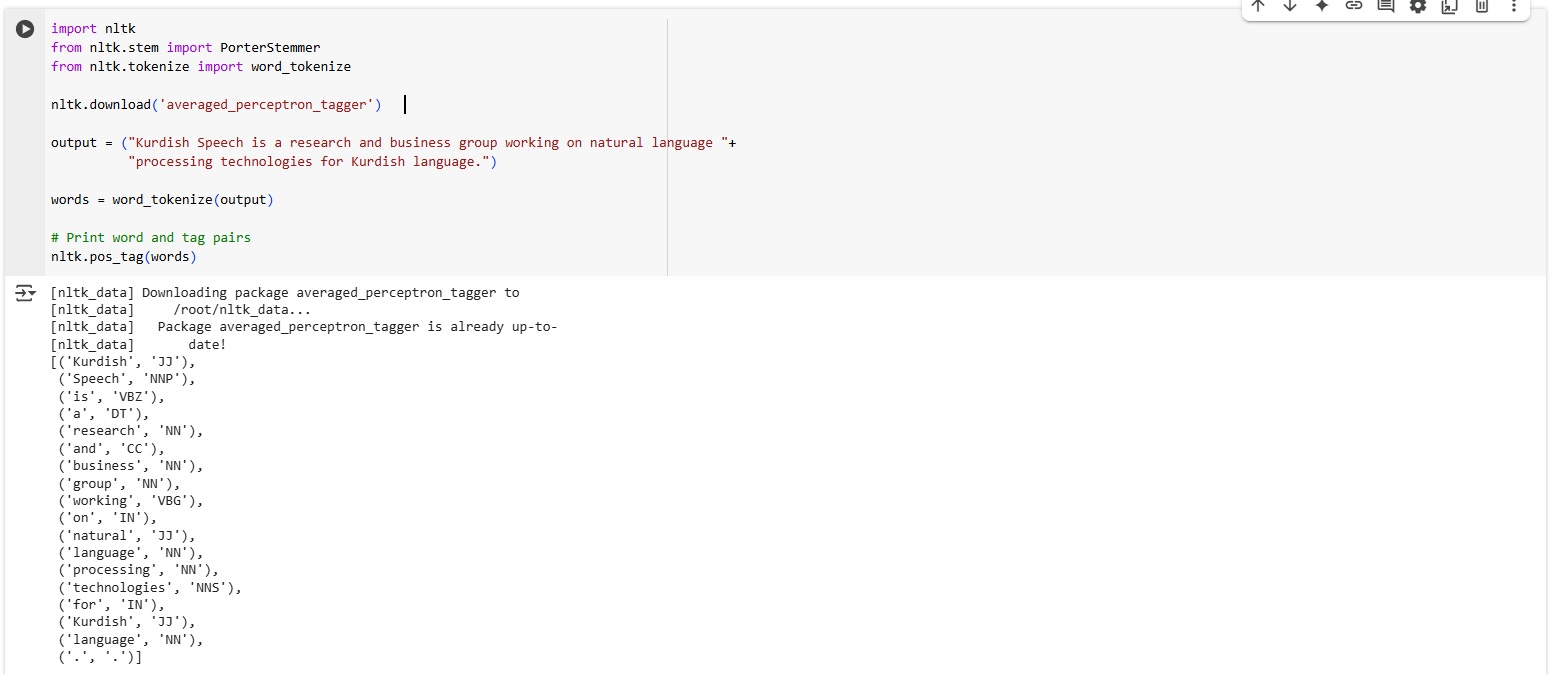
Part-Of-Speech (POS) Tagging
Part of speech (POS) analyzes the grammatical role each word plays in a sentence. In other words, it determines to which category each word (Noun, Pronoun, Adjective, Verb, Adverb, Preposition, Conjunction, and interjection) belongs. POS tags are useful when you want to assign a syntactic category to each word of the text for future analysis.
- where JJ is the tag for adjectives, NN is the tag for nouns, RB is the tag for adverbs, PRP is the tag for pronouns, and VB is the tag for verbs.
Farhad Rahimi
Researcher
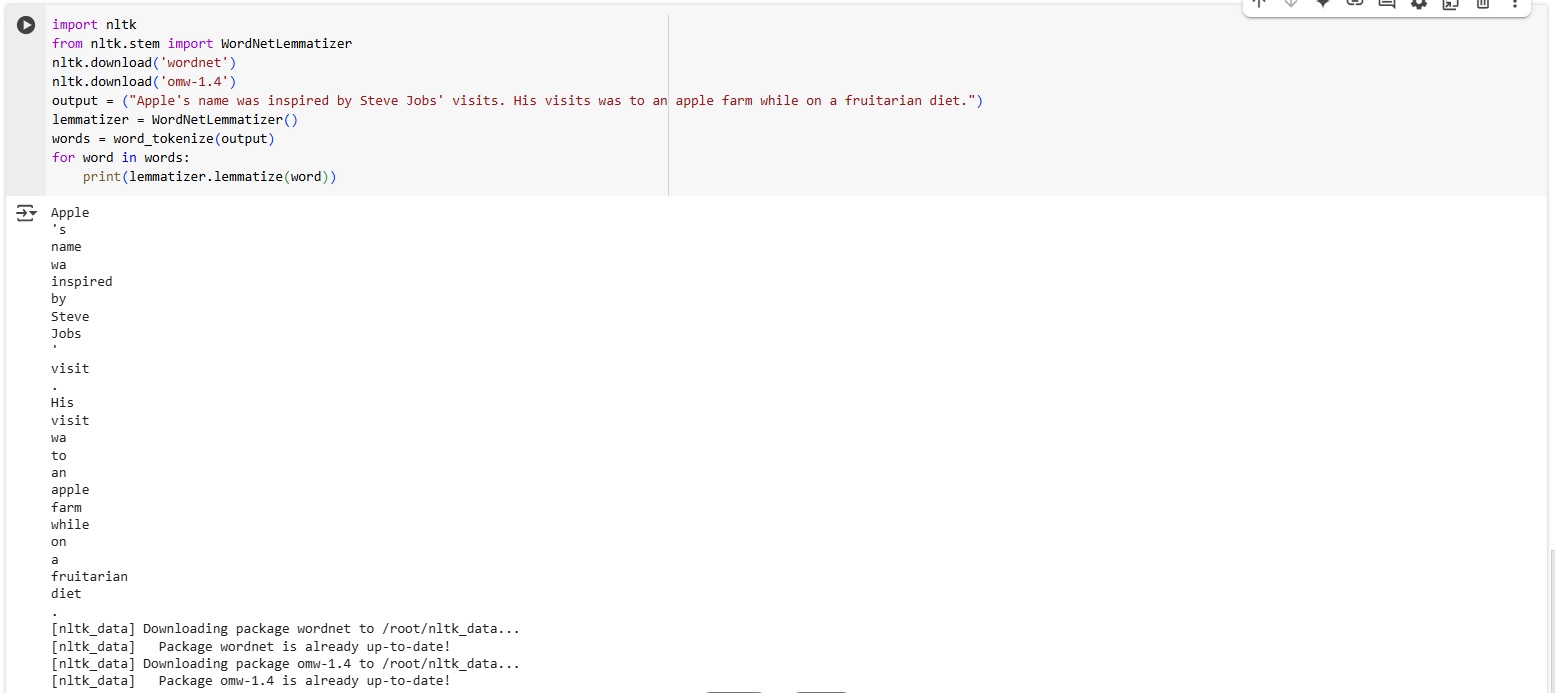
Lemmatization
Lemmatization is the process of reducing inflected forms of a word while ensuring that the reduced form belongs to a language. This reduced form or root word is called a lemma. For example, “visits”, “visiting”, and “visited” are all forms of “visit” (lemma). Here, "visit" is the lemma. The inflection of a word also reduces numbers (car vs cars). Lemmatization is an important step because it helps you reduce the inflected forms of a word so that they can be analyzed in the text more efficiently.
Farhad Rahimi
Researcher
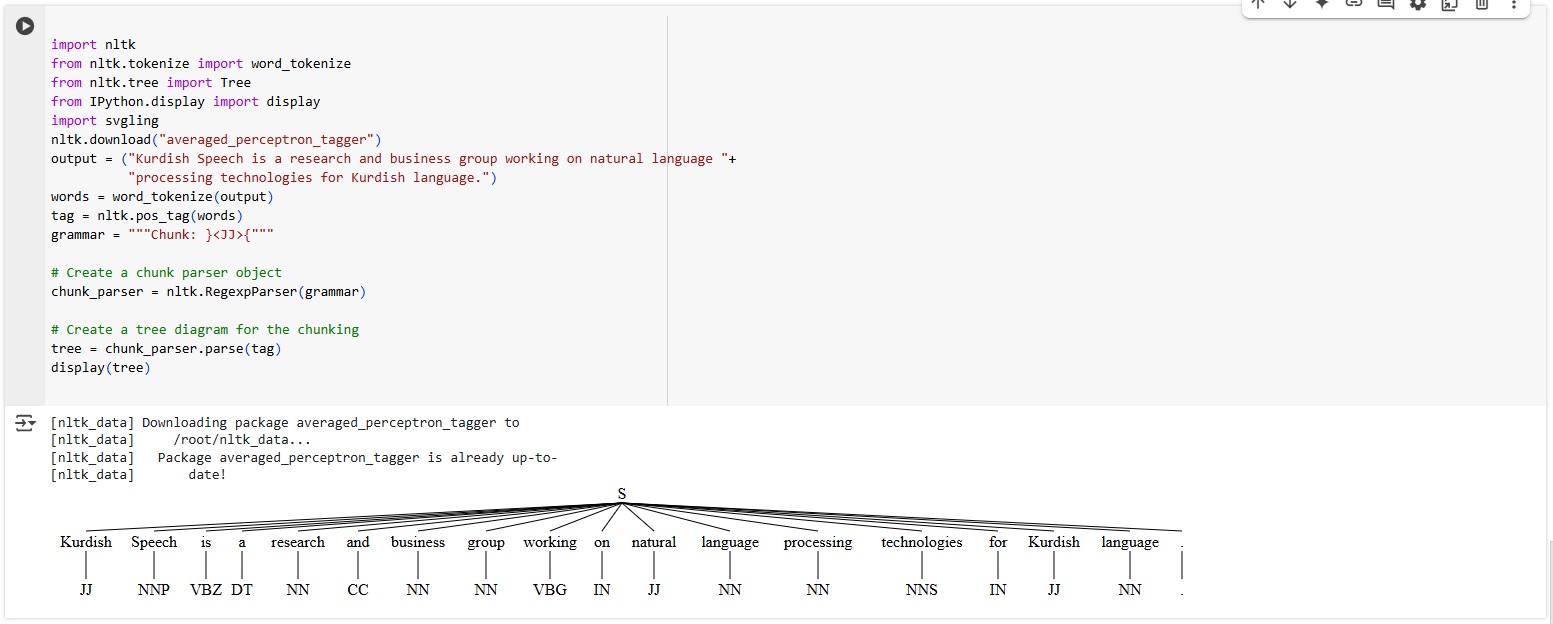
Chunking
Unlike tokenization, which allows you to identify every single word and sentence, chunking allows you to identify phrases in a textual input. Chunking allows you to extract a word or group of words that work as a unit to perform a grammatical function.

Farhad Rahimi
Researcher
Chinking
Chinking is often used together with chunking. While chunking is used to identify and find a pattern, chinking is used to exclude a pattern.
Farhad Rahimi
Researcher
Named Entity Recognition (NER)
A named entity is an object’s assigned name, for example, a person’s name, a film, a book title, or a song’s name. NLTK can recognize these named entities in a document by asking the model for a prediction. Because the performance of the models depends on the examples they were trained on, NEF might not always work perfectly and you might need to adjust the tuning based on your case.

Farhad Rahimi
Researcher
Text Cleaning
We'll convert the text to lowercase, remove punctuation, numbers, special characters, and HTML tags.
Farhad Rahimi
Researcher
Handling Contractions
Expanding contractions in the text.
Farhad Rahimi
Researcher
Handling Emojis and Emoticons
Converting emojis to their textual representation.
Farhad Rahimi
Researcher
reference
References (Additional Resources)
spaCy 101: Everything you need to know
Real Python: Natural Language Processing With spaCy in Python