
Discussion

Farhad Rahimi
Researcher
What will you create with it?
Generative AI has already revolutionized the world and it’s not slowing down. As a trained computer scientist, if you want to contribute to the revolution of Generative AI, and make an immediate impact in your organization, now is the time to enhance your expertise. Generative Artificial Intelligence (AI) represents the pinnacle of AI technology, pushing the boundaries of what was once thought impossible. Generative AI models have several capabilities.
How did we get Generative AI?
Despite the extraordinary hype created lately by the announcement of generative AI models, this technology is decades in the making, with the first research efforts dating back to the 60s. We're now at a point with AI having human cognitive capabilities, like conversation as shown by for example OpenAI ChatGPT or Bing Chat, which also uses a GPT model for the web search Bing conversations.Backing up a bit, the very first prototypes of AI consisted of typewritten chatbots, relying on a knowledge base extracted from a group of experts and represented into a computer. The answers in the knowledge base were triggered by keywords appearing in the input text. However, it soon became clear that such an approach, using typewritten chatbots, did not scale well.
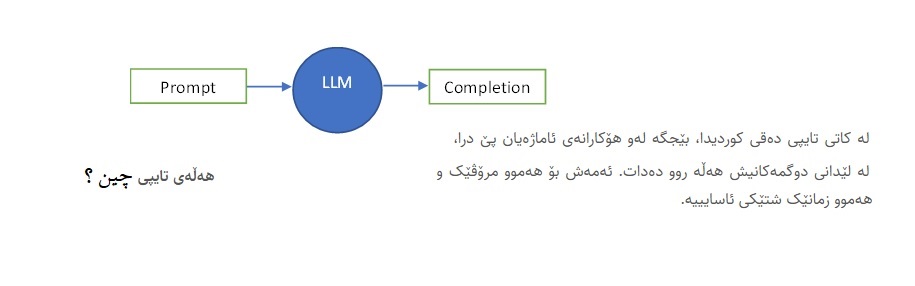
For example, to be able to use an LLM model, we give a Prompt question as input and it gives us a Completion as output.
Farhad Rahimi
Researcher
Introduction to Generative AI and Large Language Models
Generative AI is artificial intelligence capable of generating text, images and other types of content. What makes it a fantastic technology is that it democratizes AI, anyone can use it with as little as a text prompt, a sentence written in a natural language. There's no need for you to learn a language like Java or SQL to accomplish something worthwhile, all you need is to use your language, state what you want and out comes a suggestion from an AI model. The applications and impact for this are huge, you write or understand reports, write applications and much more, all in seconds.
- What generative AI is and how Large Language Models work.
- How you can leverage large language models for different use cases, with a focus on education scenarios.
Farhad Rahimi
Researcher
A statistical approach to AI: Machine Learning
A turning point arrived during the 90s, with the application of a statistical approach to text analysis. This led to the development of new algorithms – known as machine learning – capable of learning patterns from data without being explicitly programmed. This approach allows machines to simulate human language understanding: a statistical model is trained on text-label pairings, enabling the model to classify unknown input text with a pre-defined label representing the intention of the message.
Farhad Rahimi
Researcher
Neural networks and modern virtual assistants
In recent years, the technological evolution of hardware, capable of handling larger amounts of data and more complex computations, encouraged research in AI, leading to the development of advanced machine learning algorithms known as neural networks or deep learning algorithms.
Neural networks (and in particular Recurrent Neural Networks – RNNs) significantly enhanced natural language processing, enabling the representation of the meaning of text in a more meaningful way, valuing the context of a word in a sentence.
This is the technology that powered the virtual assistants born in the first decade of the new century, very proficient in interpreting human language, identifying a need, and performing an action to satisfy it – like answering with a pre-defined script or consuming a 3rd party service.
Farhad Rahimi
Researcher
How do large language models work?
let’s have a look at how large language models work, with a focus on OpenAI GPT (Generative Pre-trained Transformer) models.
- Tokenizer, text to numbers: Large Language Models receive a text as input and generate a text as output. However, being statistical models, they work much better with numbers than text sequences. That’s why every input to the model is processed by a tokenizer, before being used by the core model. A token is a chunk of text – consisting of a variable number of characters, so the tokenizer's main task is splitting the input into an array of tokens. Then, each token is mapped with a token index, which is the integer encoding of the original text chunk.
-
Predicting output tokens: Given n tokens as input (with max n varying from one model to another), the model is able to predict one token as output. This token is then incorporated into the input of the next iteration, in an expanding window pattern, enabling a better user experience of getting one (or multiple) sentence as an answer.
-
Selection process, probability distribution: The output token is chosen by the model according to its probability of occurring after the current text sequence. This is because the model predicts a probability distribution over all possible ‘next tokens’, calculated based on its training. However, not always is the token with the highest probability chosen from the resulting distribution. A degree of randomness is added to this choice, in a way that the model acts in a non-deterministic fashion - we do not get the exact same output for the same input. This degree of randomness is added to simulate the process of creative thinking and it can be tuned using a model parameter called temperature.

Farhad Rahimi
Researcher
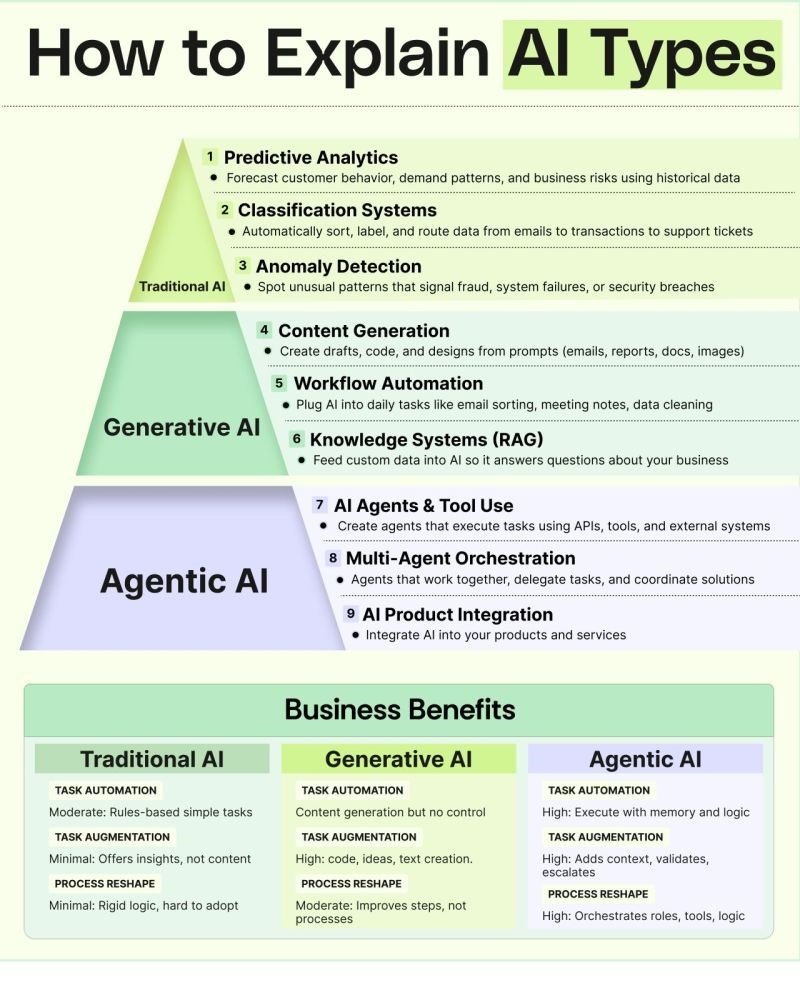
𝗧𝗿𝗮𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗔𝗜, 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜, and 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗔𝗜
🔹 𝗧𝗿𝗮𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗔𝗜: 𝗧𝗵𝗲 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻
This is where AI first made its mark—solving structured, rules-driven problems.
• 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝘃𝗲 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀: Forecast trends using historical data.
• 𝗖𝗹𝗮𝘀𝘀𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗦𝘆𝘀𝘁𝗲𝗺𝘀: Sort and categorize information automatically.
• 𝗔𝗻𝗼𝗺𝗮𝗹𝘆 𝗗𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻: Catch unusual patterns early—especially useful for fraud, risk, and system failures.
Traditional AI is reliable and rule-oriented, but limited when tasks require creativity or adaptability.
🔹 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜: 𝗖𝗿𝗲𝗮𝘁𝗶𝗻𝗴 𝗡𝗲𝘄 𝗖𝗼𝗻𝘁𝗲𝗻𝘁
This layer goes beyond analysis—it creates.
• 𝗖𝗼𝗻𝘁𝗲𝗻𝘁 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻: Drafts, summaries, designs, and more.
• 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗼𝗻: Meeting notes, email sorting, documentation.
• 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 (𝗥𝗔𝗚): Use your internal data to power context-aware answers.
Generative AI accelerates output and enhances decision-making without fully taking over processes.
🔹 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗔𝗜: 𝗧𝗵𝗲 𝗡𝗲𝘅𝘁 𝗦𝘁𝗲𝗽
This is where AI begins to act, not just analyze or generate.
• 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 & 𝗧𝗼𝗼𝗹 𝗨𝘀𝗲: Systems that trigger actions across tools and APIs.
• 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻: Multiple agents working together for complex workflows.
• 𝗔𝗜 𝗣𝗿𝗼𝗱𝘂𝗰𝘁 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻: Embedding AI logic directly into products and services.
Agentic AI introduces autonomy—handling tasks with memory, reasoning, and coordination.
𝗪𝗵𝗲𝗿𝗲 𝘁𝗵𝗲 𝗥𝗲𝗮𝗹 𝗕𝘂𝘀𝗶𝗻𝗲𝘀𝘀 𝗩𝗮𝗹𝘂𝗲 𝗖𝗼𝗺𝗲𝘀 𝗜𝗻
• 𝗧𝗿𝗮𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗔𝗜: Automates simple, rule-based tasks.
• 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜: Enhances creativity, speeds up content-driven work.
• 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗔𝗜: Orchestrates workflows across teams, tools, and systems.
Understanding these layers helps you decide what to adopt now and what to prepare for next.
Farhad Rahimi
Researcher
𝟴 𝗧𝘆𝗽𝗲𝘀 𝗼𝗳 𝗟𝗟𝗠𝘀 𝗣𝗼𝘄𝗲𝗿𝗶𝗻𝗴 𝗧𝗼𝗱𝗮𝘆’𝘀 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀
As AI agents become smarter and more capable, the models behind them are evolving just as quickly. We’re no longer relying on one “all-purpose” model — modern AI systems use a mix of specialized architectures built for reasoning, vision, planning, action, and deeper concept understanding.
Here’s a simple, clear rundown of the 8 major LLM types shaping the next wave of AI agents:
🔵 𝟭. 𝗚𝗣𝗧 – 𝗚𝗲𝗻𝗲𝗿𝗮𝗹 𝗣𝗿𝗲𝘁𝗿𝗮𝗶𝗻𝗲𝗱 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀
The familiar backbone. Great at generating text, answering questions, and holding conversations thanks to large-scale pretraining.
🟢 𝟮. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀
Think of it as a team of specialists. A gating system picks the right expert for each task, making it efficient and highly scalable.
🔷 𝟯. 𝗟𝗥𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹𝘀
Built for deeper thinking. They break problems down, reason step-by-step, and validate their own answers.
🟠 𝟰. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀
The bridge between images and text. Essential for multimodal agents, robotics, and any AI that needs to “see” and “understand.”
🟣 𝟱. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀
Compact, fast, and cost-effective. Perfect for edge devices, private deployments, or systems that need quick responses.
🟡 𝟲. 𝗟𝗔𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀
Focused on doing, not just knowing. They plan, call tools, interact with APIs, and work toward a goal.
🔵 𝟳. 𝗛𝗥𝗠 – 𝗛𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝗶𝗰𝗮𝗹 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹𝘀
Combine big-picture planning with fast local decision-making — ideal for long, multi-step tasks.
🟧 𝟴. 𝗟𝗖𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗖𝗼𝗻𝗰𝗲𝗽𝘁 𝗠𝗼𝗱𝗲𝗹𝘀
Go a layer deeper. They represent richer world concepts and generate more coherent outputs using structured decoding and diffusion-like approaches.
Farhad Rahimi
Researcher
40 Large Language Model Benchmarks and The Future of Model Evaluation
40 LLM Benchmarks
| Benchmark | Summary | Category |
| MMLU (Massive Multitask Language Understanding) | A 57-subject multiple-choice QA test evaluating broad world knowledge and reasoning, covering topics from math and history to law. | Reasoning (Knowledge) |
| ARC-AGI (Abstraction & Reasoning Corpus) | A set of abstract visual puzzles (François Chollet’s ARC) intended to measure progress toward general AI by testing pattern recognition and analogical reasoning beyond brute-force learning. | Reasoning (Analogy) |
| Thematic Generalization | Tests whether an LLM can infer a hidden “theme” or rule from a few example and counterexample prompts, requiring generalization from limited data. | Reasoning (Concept Learning) |
| Misguided Attention | A collection of reasoning problems designed with misdirective or irrelevant information to challenge an LLM’s ability to stay focused on the correct cues and avoid being tricked. | Reasoning (Robustness) |
| WeirdML | Presents unconventional machine-learning style tasks (e.g. identifying shuffled images, odd ML problems) that demand careful, truly understanding-based reasoning from LLMs. | Reasoning (Unconventional) |
| GPQA-Diamond | A graduate-level “Google-Proof” Q&A benchmark of ~200 expert-written questions in physics, biology, and chemistry – extremely challenging science problems intended to resist memorization. | Reasoning (Scientific) |
| SimpleQA | A factual QA benchmark from OpenAI with short, fact-seeking questions, testing an LLM’s ability to provide accurate, concise answers to straightforward queries. | Reasoning (Factual) |
| TrackingAI – IQ Bench | An IQ test for AIs using verbalized human IQ questions (e.g. Mensa puzzles) to estimate models’ cognitive ability; measures how models handle logic, pattern-matching, and problem-solving typical of IQ exams. | Reasoning (Cognitive) |
| Humanity’s Last Exam (HLE) | A new ultra-hard benchmark curated by domain experts (“last exam” for AI) with rigorous questions across math, science, etc., where current top models score <10% – intended as a final obstacle indicating near-AGI when surpassed. | Reasoning (Advanced) |
| MathArena | A platform using fresh math competition and Olympiad problems to rigorously assess LLMs’ mathematical reasoning; designed to avoid contamination by testing models right after contest problems are released. | Reasoning (Math) |
| MGSM (Multilingual Grade School Math) | A multilingual version of grade-school math word problems (GSM8K translated into 10 languages) to test math reasoning across languages. (NOTE: this is considered saturated as many models already achieve high chain-of-thought performance) | Reasoning (Math) |
| BBH (Big-Bench Hard) | A subset of 23 especially challenging tasks from the BIG-Bench suite that earlier models (like GPT-3) failed at, used to evaluate advanced compositional reasoning and out-of-distribution generalization. (Considered saturated.) | Reasoning (Mixed Hard Tasks) |
| DROP (Discrete Reasoning Over Paragraphs) | A reading comprehension benchmark of 96K adversarial questions requiring discrete reasoning (e.g. arithmetic, date sorting) over text passages – models must combine reading with symbolic reasoning. | Reasoning (Reading & Math) |
| Context-Arena | A leaderboard focusing on long-context understanding: it visualizes LLM performance on tasks like long document question answering and multi-turn reference resolution (such as OpenAI’s MRCR test for long-context recall). | Reasoning (Long Context) |
| Fiction-Live Bench (Short Story Creative Writing) | A creative writing benchmark that asks models to write short stories incorporating ~10 specific required elements (characters, objects, themes, etc.), evaluating how well an LLM maintains narrative coherence while obeying content constraints. | Longform Writing (Creative) |
| AidanBench | An open-ended idea generation benchmark where models answer creative questions with as many unique, coherent ideas as possible – penalizing mode collapse and repetitive answers, with effectively no ceiling on the score for truly novel outputs. | Creative Thinking |
| EQ-Bench (Emotional Intelligence Benchmark) | Evaluates an LLM’s grasp of emotional and social reasoning through tasks like empathetic dialogue or creative writing with emotional nuance, scored by an LLM judge on facets of emotional intelligence. | Longform Writing (Emotional IQ) |
| HumanEval | OpenAI’s coding benchmark of 164 hand-written Python problems where the model must produce correct code for a given specification, used to measure functional correctness in basic programming. | Coding |
| Aider Polyglot Coding | A code-editing benchmark from Aider: tasks 225 coding challenges from Exercism across C++, Go, Java, JavaScript, Python, and Rust, measuring an LLM’s ability to follow instructions to modify or write code in multiple languages. | Coding (Multilingual) |
| BigCodeBench | A large benchmark of 1,140 diverse, realistic programming tasks (with complex function calls and specs) for evaluating true coding capabilities beyond simple algorithmic problems. | Coding |
| WebDev Arena | An arena-style coding challenge where two LLMs compete head-to-head to build a functional web application from the same prompt, allowing evaluation of practical web development skills via human pairwise comparisons. | Coding (Web Dev) |
| SciCode | A research-oriented coding benchmark with 338 code problems drawn from scientific domains (math, physics, chemistry, biology) – it tests if models can write code to solve challenging science problems at a PhD level. | Coding (Scientific) |
| METR (Long Tasks) | An evaluation framework proposing to measure AI performance by task length: it examines the longest, most complex tasks an AI agent can complete autonomously, as a proxy for general capability growth. | Agentic Behavior (Long-Horizon) |
| RE-Bench (Research Engineering) | A benchmark from METR that pits frontier AI agents against human ML engineers on complex ML research & engineering tasks (like reproducing experiments), gauging how close AI is to automating ML R&D work. | Agentic Behavior (R&D Tasks) |
| PaperBench | OpenAI’s benchmark evaluating if AI agents can replicate SOTA AI research – agents are given recent ML papers (e.g. ICML 2024) and tasked to reimplement and reproduce the results from scratch, testing planning, coding, and experiment execution. |
Agentic Behavior (Research Automation)
|
| SWE-Lancer | A benchmark of 1,403 real freelance software engineering tasks (from Upwork, worth $1M total) to assess whether advanced LLMs can complete end-to-end coding jobs – mapping AI performance directly to potential earnings. |
Agentic Behavior (Real-World Coding)
|
| MLE-Bench | OpenAI’s Machine Learning Engineer benchmark with 75 real-world ML tasks (e.g. Kaggle competitions) – it evaluates how well an AI agent can handle the end-to-end workflow of ML problems, including data handling, training, and analysis. | Agentic Behavior (AutoML) |
| SWE-Bench | A Princeton/OpenAI benchmark of 2,294 GitHub issues (with associated codebases) – models must act as software agents that read a repo, then write patches to resolve the issue, passing all tests; it closely mirrors real developer workflows. |
Agentic Behavior (Code Maintenance)
|
| Tau-Bench (Tool-Agent-User) | Sierra AI’s benchmark of interactive agents in realistic scenarios – the agent converses with a simulated user and uses tools to accomplish tasks in domains like retail (cancel orders, etc.) or airlines, testing multi-turn tool use and dynamic planning. | Agentic Behavior (Tool Use) |
| XLANG Agent | An open framework and leaderboard (HKU) for multi-lingual agents – it evaluates agents’ ability to perform tasks involving multiple languages, reflecting an agent’s versatility and reasoning across language barriers. |
Agentic Behavior (Multilingual Agents)
|
| Balrog-AI | A benchmark for agentic reasoning in games: tasks LLMs (and VLMs) with playing a text-based adventure or completing long-horizon game objectives, evaluating planning, memory, and decision-making in an interactive environment. | Agentic Behavior (Game) |
| Snake-Bench | An LLM-as-Snake-Player challenge where models control a snake in a simulated Snake game; multiple LLM “snakes” compete, testing the model’s ability to strategize and react in a turn-based environment with long-term consequences. | Agentic Behavior (Game) |
| SmolAgents LLM | A HuggingFace leaderboard that evaluates small-scale autonomous agent tasks (a mini subset of the GAIA agent benchmark and some math tasks) – ranking how both open-source and closed models perform when deployed as minimalistic agents. | Agentic Behavior (Agents) |
| MMMU (Massive Multi-discipline Multimodal Understanding) | A comprehensive multimodal benchmark with college-level problems that include both text and images (diagrams, charts, etc.), requiring models to integrate visual information with advanced subject knowledge and reasoning. | Multimodal (Reasoning) |
| MC-Bench (Minecraft Benchmark) | An interactive benchmark where LLMs generate Minecraft builds or solutions that are evaluated via human comparisons (like a Minecraft Arena); it tests spatial reasoning and creativity in a visual sandbox, making evaluation more dynamic and open-ended. | Multimodal (Interactive) |
| SEAL by Scale (Multi-Challenge Leaderboard) | Scale AI’s multi-challenge evaluation leaderboard that aggregates a wide range of tasks into one ranking – providing a holistic comparison of models across diverse challenges (the “MultiChallenge” track showcases overall capability). | Meta-Benchmarking (Multi-Task) |
| LMArena (Chatbot Arena) | A crowd-sourced Elo-style leaderboard where models duel in pairwise chat conversations (judged by users); it reveals general quality/preferences by having models compete in open-ended dialogue. | Meta-Benchmarking (Human Pref) |
| LiveBench | An evergreen evaluation suite updated monthly with fresh, contamination-free test data across 18 tasks (math, coding, reasoning, language, instruction following, data analysis). It provides an up-to-date benchmark to track model progress over time. | Meta-Benchmarking (Multi-Task) |
| OpenCompass | An open-source LLM evaluation platform supporting 100+ datasets. It serves as a unified framework and leaderboard to benchmark a wide range of models (GPT-4, Llama, Mistral, etc.) on many tasks, enabling apples-to-apples model comparisons. | Meta-Benchmarking (Platform) |
| Dubesor LLM | A personal but extensive benchmark aggregator (named “rosebud” backwards): one individual’s ongoing comparison of various models across dozens of custom tasks, combined into a single weighted score for each model. | Meta-Benchmarking (Aggregator) |
Ref : https://arize.com/blog/llm-benchmarks-mmlu-codexglue-gsm8k